Tekoäly ja koneoppiminen kyberturvallisuudessa
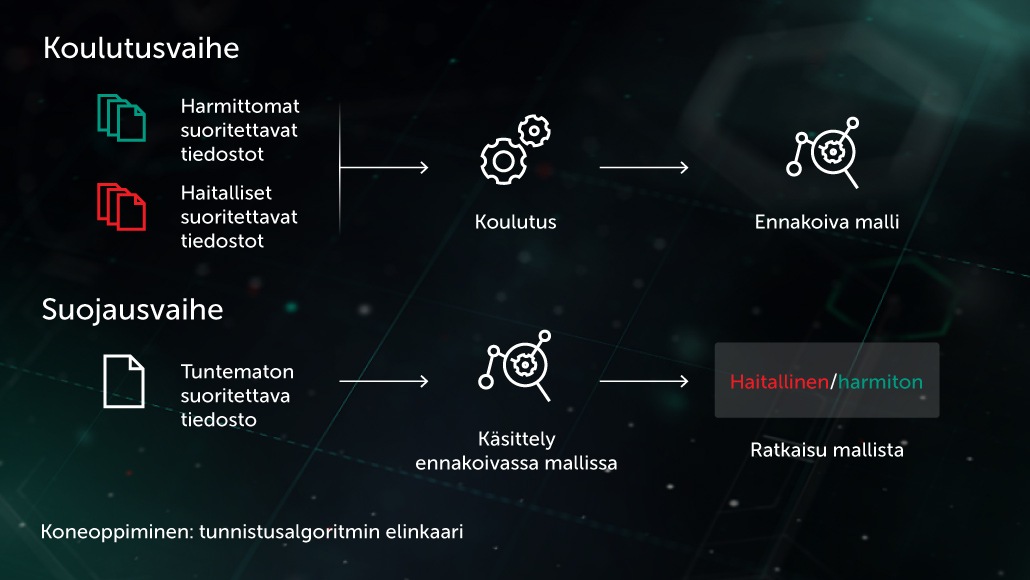
Tekoälyn edelläkävijä Arthur Samuel kuvasi tekoälyä menetelmien ja tekniikoiden joukoksi, joka ”antaa tietokoneille kyvyn oppia ilman erillistä ohjelmointia”. Haittaohjelmien torjuntaa koskevan valvotun oppimisen erityistapauksessa tehtävä voidaan muotoilla seuraavasti: kun syötteenä on joukko objektien ominaisuuksia \( X \) ja niitä vastaavat objektien merkinnät \( Y \), luodaan malli, joka tuottaa oikeat merkinnät \( Y' \) aiemmin tuntemattomille testiobjekteille \( X' \). \( X \) voi olla joitain tiedoston sisältöä tai käyttäytymistä kuvaavia ominaisuuksia (tiedostotilastot, luettelo käytetyistä API-funktioista jne.), ja merkinnät \( Y \) voivat olla yksinkertaisesti ”haittaohjelma” tai ”hyvänlaatuinen” (monimutkaisemmissa tapauksissa voimme olla kiinnostuneita tarkemmasta luokittelusta, kuten virus, troijalaisen lataaja, mainosohjelma jne.). Jos kyseessä on valvomaton oppiminen, tärkeämpää on paljastaa datan piilotettu rakenne, esim. löytää samankaltaisten kohteiden tai hyvin korreloivien ominaisuuksien ryhmät.
Kasperskyn monitasoinen uuden sukupolven suojaus käyttää laajasti tekoälyn menetelmiä kuten koneoppimista kaikissa tunnistuksen vaiheissa, aina infrastruktuurin saapuvan tiedostovirran esikäsittelyyn käytettävistä skaalautuvista ryhmittelymenetelmistä toiminnan tunnistuksen tehokkaisiin ja tiiviisin syvien neuroverkkojen malleihin, jotka toimivat suoraan käyttäjien koneilla. Nämä teknologiat on suunniteltu vastaamaan useisiin reaalimaailman kyberturvallisuussovellusten tärkeisiin vaatimuksiin, joita ovat muun muassa erittäin alhainen väärien positiivisten tulosten määrä, mallien tulkittavuus ja vastustajien kestävyys.
Tutustutaanpa muutamiin tärkeimpiin koneoppimiseen perustuviin tekniikoihin, joita Kasperskyn päätepistetuotteissa käytetään:
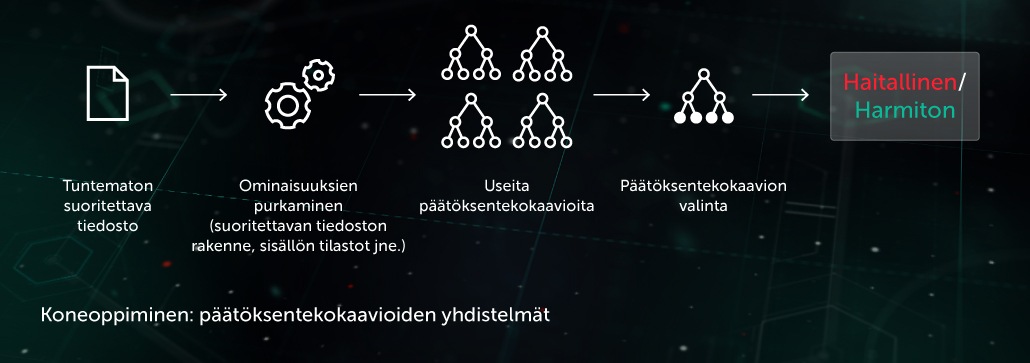
Päätöksentekokaavioiden yhdistelmä
Tässä tavassa ennakoiva malli on päätöksentekokaavioiden yhdistelmän muodossa (esim. random forest- tai gradient boosted -kaaviot). Kaaviossa jokainen muu kuin lehtisolmu sisältää kysymyksen tiedoston ominaisuuksista, ja lehtisolmuissa on kaavion lopullinen päätös kohteesta. Testausvaiheessa malli käy kaavion läpi vastaamalla solmuissa oleviin kysymyksiin käsiteltävän kohteen vastaavilla ominaisuuksilla. Viimeisessä vaiheessa lasketaan useiden kaavioiden päätösten keskiarvo algoritmikohtaisella tavalla, jotta saadaan kohteelle lopullinen päätös.
Malli voi käyttää suoritusta edeltävää ennakoivaa suojausvaihetta päätepisteen päässä. Yksi tämän tekniikan sovelluksista on Cloud ML for Android, jota käytetään mobiililaitteiden uhkien tunnistamiseen.
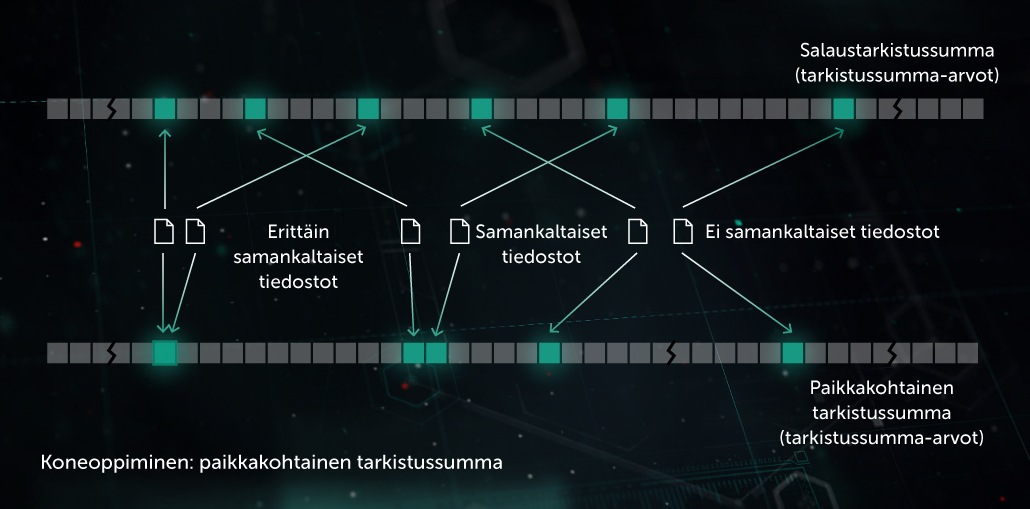
Samankaltaisuuden tarkistussumma (paikkakohtainen tarkistussumma)
Aikaisemmin haittaohjelmien ”jalanjälkien” luomiseen käytetyt tarkistussummat olivat herkkiä jokaiselle pienellekin tiedostossa tapahtuneelle muutokselle. Haittaohjelmien kirjoittajat käyttivät tätä epäkohtaa hyväkseen hämäystekniikoissa, kuten palvelinpuolen polymorfisuudessa: pienetkin muutokset haittaohjelmassa piilottivat sen. Samankaltaisuuden tarkistussumma (tai paikkakohtainen tarkistussumma) on tekoälyyn perustuva menetelmä samankaltaisten haitallisten tiedostojen tunnistamiseen. Järjestelmä poimii tätä varten tiedoston ominaisuudet ja käyttää ortogonaaliseen projektioon perustuvaa oppimista tärkeimpien ominaisuuksien valintaan. Sen jälkeen käytetään koneoppimiseen perustuvaa pakkaamista, jotta samankaltaisten ominaisuuksien arvovektorit muunnetaan samankaltaisiksi tai identtisiksi malleiksi. Tämä menetelmä antaa hyvän yleiskuvan ja pienentää huomattavasti tunnistuksen tietueiden kannan kokoa, sillä yksi tietue voi nyt tunnistaa polymorfisten haittaohjelmien koko ryhmän.
Malli voi käyttää suoritusta edeltävää ennakoivaa suojausvaihetta päätepisteen päässä. Sitä käytetään Similarity Hash Detection System -järjestelmässämme.
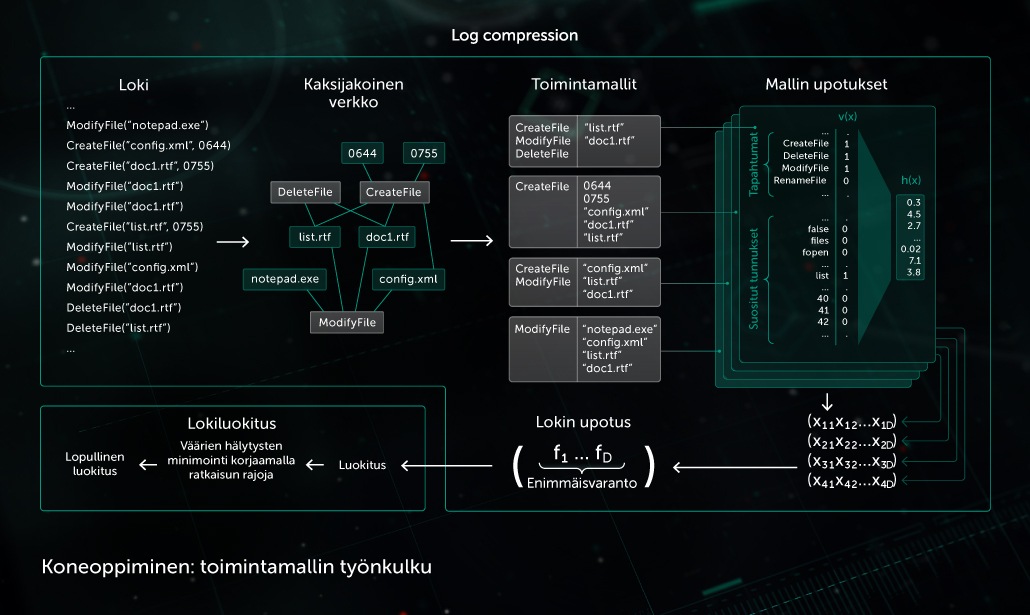
Toimintamalli
Valvontakomponentti tuottaa toimintalokin, jossa on sarja järjestelmän tapahtumia prosessin suorituksen ajalta sekä vastaavat argumentit. Jotta voidaan tunnistaa haitallinen toiminta seuratuista lokitiedoista, malli pakkaa hankitun tapahtumien sarjan joukoksi binaarivektoreita ja kouluttaa syvän neuroverkon erottamaan puhtaat ja haitalliset lokit.
Toimintamallin tekemää kohteiden luokittelua käytetään Kasperskyn tuotteiden staattisissa ja dynaamisissa tunnistusmoduuleissa päätepisteen päässä.
Tekoälyllä on yhtä tärkeä rooli myös asianmukaisen laboratoriokohtaisen haittaohjelmien käsittelyinfrastruktuurin rakentamisessa. Kaspersky käyttää sitä infrastruktuurissa seuraaviin tarkoituksiin:
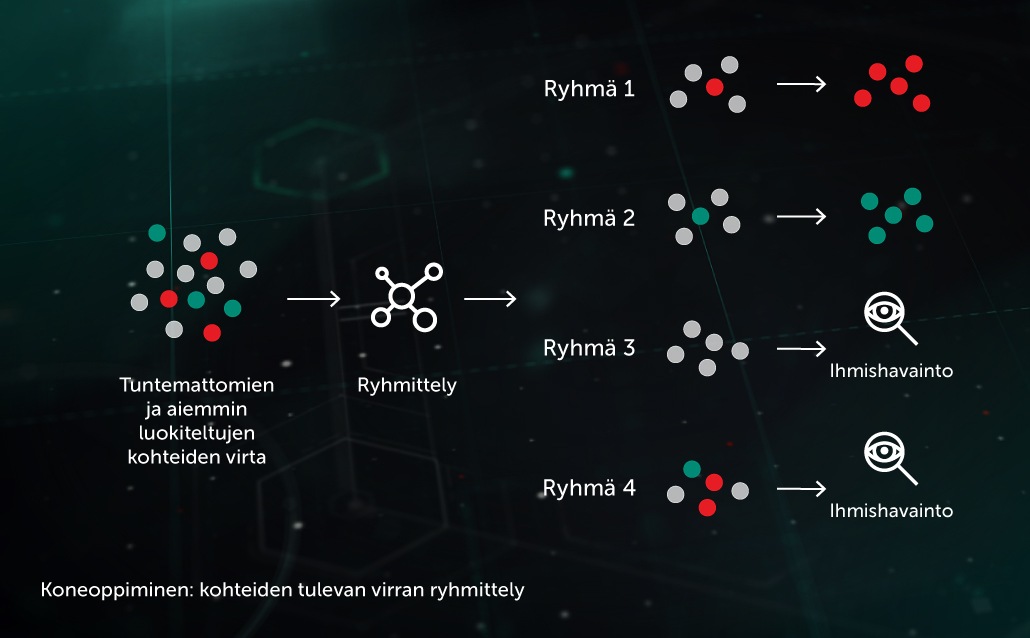
Saapuvan virran ryhmittely
Koneoppimispohjaisten ryhmittelyalgoritmien avulla voimme erotella infrastruktuuriimme saapuvat suuret tuntemattomien tiedostojen määrät tehokkaasti sopivaksi määräksi ryhmiä, joista osan voi käsitellä automaattisesti, koska niiden sisällä on jo merkitty kohde.
Laajat luokittelumallit
Jotkin tehokkaimmista luokittelumalleista (kuten suuri määrä satunnaisia päätöksentekokaavioita) vaativat paljon resursseja (suoritinaikaa, muistia) sekä kalliit ominaisuuksien poimintatoiminnot (esim. tarkat toimintalokit voivat edellyttää käsittelyä testiympäristössä). Siksi on tehokkaampaa pitää ja suorittaa mallit laboratoriossa ja suodattaa sen jälkeen mallien avulla hankitut tiedot kouluttamalla kevyt luokittelumalli suuremman mallin tuottamien päätösten perusteella.
Tekoälyn koneoppimisnäkökohtien käyttöön liittyvä turvallisuus
Kun koneoppimisen algoritmit päästetään laboratoriosta todelliseen maailmaan, ne voivat olla alttiita monenlaisille hyökkäyksille, jotka on suunniteltu pakottamaan tekoälyjärjestelmät tahallisiin virheisiin. Hyökkääjä voi myrkyttää koulutusdatajoukon tai takaisinmallintaa mallin koodin. Lisäksi hakkerit voivat väsytyshyökkäyksillä ”murtaa” koneoppimismalleja erityisesti kehitettyjen ”vastustajien tekoälyjärjestelmien” avulla, jotka voivatluoda automaattisesti useita hyökkäysnäytteitä ja käynnistää ne suojausratkaisua tai purettua koneoppimismallia vastaan, kunnes mallin heikko kohta löydetään. Tällaisten hyökkäysten vaikutus tekoälypohjaisiin haittaohjelmien torjuntajärjestelmiin voi olla tuhoisa: tunnistamatta jäänyt troijalainen voi tartuttaa miljoonia laitteita ja aiheuttaa miljoonien menetykset.
Tästä syystä tekoälyä turvallisuusjärjestelmissä käytettäessä on otettava huomioon joitakin keskeisiä näkökohtia:
- Tietoturvaratkaisujen toimittajan on tunnettava ja otettava huomioon keskeiset vaatimukset, jotka koskevat tekoälytoimintojen suorituskykyä todellisessa ja mahdollisesti vihamielisessä maailmassa: näihin kuuluu vahva suojaus mahdollisia hyökkääjiä vastaan. Koneoppimisen/tekoälyn avulla toteutettavien turvallisuusauditointien ja Red Team -toiminnan olisi oltava keskeisiä osatekijöitä kehitettäessä turvallisuusjärjestelmiä, joissa käytetään tekoälyn osa-alueita.
- Arvioitaessa tekoälyn elementtejä käyttävän ratkaisun turvallisuutta, on kysyttävä, missä määrin ratkaisu on riippuvainen kolmannen osapuolen tiedoista ja arkkitehtuurista, sillä monet hyökkäykset perustuvat kolmannen osapuolen syötteisiin (kuten uhkatiedustelun syötteet, julkiset tietokannat, valmiiksi koulutetut ja ulkoistetut tekoälymallit).
- Koneoppimis-/tekoälymenetelmiä ei pitäisi pitää ihmeratkaisuna, vaan niiden on oltava osa monikerroksista turvallisuusratkaisua, jossa toisiaan täydentävät suojausteknologiat ja inhimillinen asiantuntemus työskentelevät yhdessä ja tukevat toisiaan.
On tärkeää huomata, että vaikka Kasperskyllä on laaja kokemus tekoälyn osa-alueiden, kuten koneoppimisen ja siihen kuuluvan syväoppimisen, tehokkaasta hyödyntämisestä kyberturvallisuusratkaisuissaan, nämä teknologiat eivät ole todellista tekoälyä tai yleistä tekoälyä (AGI). On vielä pitkä matka siihen, että koneet voivat toimia itsenäisesti ja suorittaa useimmat tehtävät täysin omatoimisesti. Sitä odotellessa lähes kaikki tekoälyn osa-alueet kyberturvallisuudessa edellyttävät inhimillisten ammattilaisten ohjausta ja asiantuntemusta, jotta järjestelmiä voidaan kehittää ja jalostaa ja niiden valmiuksia kasvattaa ajan myötä.
Lisätietoja yleisistä koneoppimisen/ tekoälyn algoritmeihin kohdistuvista hyökkäyksistä ja näiltä uhilta suojautumisesta on white paperissamme AI under Attack: How to Secure Machine Learning in Security Systems.

